DRL:Deep Reinforcement Learning
یادگیری تقویتی عمیقDRL:Deep Reinforcement Learning
یادگیری تقویتی عمیق
چگونه الگوریتم های یادگیری تقویتی عمیق را انتخاب کنیم؟
با توجه به تنوع زیاد الگوریتم های تقویتی عمیق ر این مقاله به صورت خلاصه الگوریتمها و مزایا و موارد استفاده آنها را جمع بندی کرده است.
https://arxiv.org/abs/2407.20917
https://rl-picker.github.io/

کنترل TD خارج از سیاست - یادگیری Q (Q – Learning)
در این بخش، الگوریتم کنترل TD خارج از سیاست به نام یادگیری Q را یاد خواهیم گرفت. این یکی از الگوریتم های بسیار محبوب در یادگیری تقویتی است و خواهیم دید که این الگوریتم در فصل های دیگر نیز مطرح میشود. یادگیری Q یک الگوریتم سیاست خارج از سیاست است ، به این معنی که ما از دو سیاست مختلف استفاده میکنیم، یک سیاست برای رفتار در
محیط (انتخاب یک عمل در محیط) و دیگری برای پیدا کردن سیاست بهینه است.
یاد گرفتیم که در روش SARSA، اقدام a را در
حالت s با استفاده از سیاست epsilongreedy انتخاب میکنیم،
به حالت s’ بعدی حرکت می کنیم. و مقدار Q را با استفاده ازفرمول
زیر به روز رسانی میکنیم: 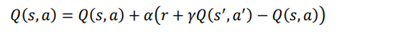
در معادله بالا، به منظور محاسبه مقدار Q جفت حالت-عمل بعدی، Q(s’ , a’ ) باید یک عمل را انتخاب کنیم. بنابراین، عمل را با استفاده از همان سیاست epsilongreedy انتخاب میکنیم و مقدار Q جفت بعدی state-action را به روز میکنیم.
اما بر خلاف SARSA، در یادگیری Q، ما از دو سیاست مختلف استفاده میکنیم. یکی سیاست epsilongreedy است و دیگری یک سیاست حریصانه است. برای انتخاب یک عمل در محیط از یک سیاست حریصانه اپسیلون استفاده میکنیم، اما برای به روزرسانی ارزش Q جفت حالت بعدی ، از یک سیاست حریصانه استفاده میکنیم.
به عبارت دیگر، اقدام a را در حالت s با استفاده از سیاست حریصانه اپسیلون انتخاب میکنیم و به سمت s’ در حالت بعدی حرکت میکنیم و مقدار Q را با استفاده از قانون به روز رسانی نشان داده شده در زیر به روز میکنیم:
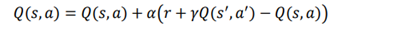
در معادله قبلی، به منظور محاسبه مقدار Q جفت عمل حالت بعدی Q(s’,a’)، باید یک عمل را انتخاب کنیم. در اینجا، عمل را با استفاده از سیاست حریصانه انتخاب میکنیم و با به روز رسانی ارزش Q جفت بعدی حالت اقدام بدست میاید. می دانیم که سیاست حریصانه همیشه عملی را انتخاب میکند که حداکثر مقدار را دارد. بنابراین، ما می توانیم معادله را به شکل زیر تغییر دهیم:
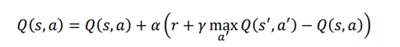
همانطور که میتوانیم از معادله قبلی مشاهده کنیم، اپراتور max حداکثر را نشان می دهد اگر در حالت s’ و عمل a’ ، ماکزیمم Q را داشته باشیم. بنابراین، برای خلاصه کردن، در روش یادگیری Q، یک عمل را در محیط با استفاده از سیاست حریصانه اپسیلون انتخاب میکنیم ، اما در حالی که محاسبه مقدار Q از جفت state-action بعدی با استفاده از سیاست حریصانه است . بنابراین، قانون به روز رسانی یادگیری Q به شکل زیر داده میشود:
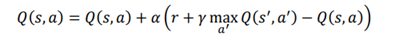
بیایید این را با محاسبه دستی مقدار Q با استفاده از قانون به روز رسانی یادگیری Q بهتر درک کنیم . از همان مثال دریاچه یخ زده استفاده کنیم. ما Q خود را در جدول با مقادیر تصادفی مقداردهی اولیه میکنیم. شکل 5.13 محیط دریاچه یخ زده، همراه با جدول Q حاوی مقادیر تصادفی را نشان میدهد:
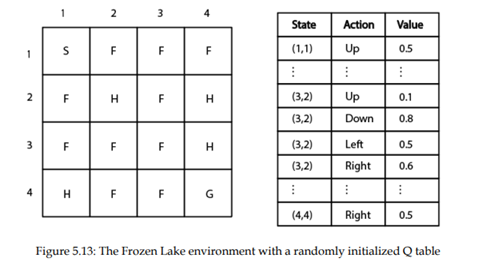
فرض کنید در حالت(3،2). هستیم در حال حاضر، باید برخی از اقدامات را در این حالت انتخاب کنیم. چگونه میتوانیم یک عمل را انتخاب کنیم؟ یک عمل را با استفاده از سیاست حریصانه اپسیلون انتخاب میکنیم. بنابراین، با احتمال اپسیلون، یک عمل تصادفی را انتخاب میکنیم و با احتمال 1-اپسیلون بهترین عمل را انتخاب کنید که حداکثر مقدار Q را داشته باشد.
فرض کنید از احتمال 1-اپسیلون استفاده میکنیم و بهترین عمل را انتخاب میکنیم. بنابراین، در حالت (3،2)، عمل حرکت به پایین را انتخاب میکنیم زیرا به بالاترین ارزش Q در مقایسه با اقدامات دیگر در ان حالت میرسیم، که شکل 5.14 نشان می دهد:
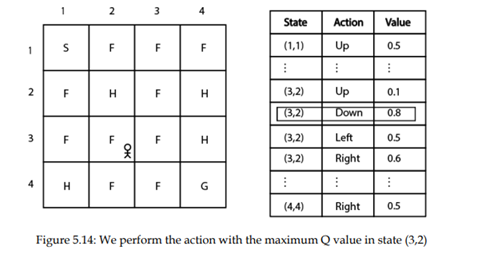
خوب، بنابراین، با انجام عمل پایین در حالت (3.2) و حرکت به حالت بعدی (4.2)، میرویم طبق شکل 5.15 نشان می دهد
بنابراین، در حالت (3.2) به حالت بعدی (4.2) حرکت میکنیم و پاداش r 0 را دریافت میکنیم. بیایید نرخ یادگیری α را برابر با 0.1 و عامل تخفیف گاما را برابر با 1 نگه داریم. چگونه می توانیم به روز رسانی مقدار Qرا انجام دهیم؟
بیایید قانون به روز رسانی یادگیری Q خود را به یاد بیاوریم:
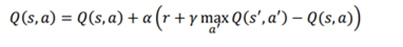
برای محاسبه مقادیر را به صورت زیر فرض کردیم:
r=0 , α= 0.1 , γ= 1

به طور مشابه، ما مقدار Q را برای تمام جفت های state-action به روز می کنیم. یعنی یک عمل را در محیط با استفاده از یک سیاست حریصانه اپسیلون انتخاب میکنیم ، و در حالی که برای به روز رسانی مقدار Q ا از جفت بعدی حالت اقدام از سیاست حریصانه استفاده خواهیم کرد.
بنابراین، به این ترتیب، تابع Q را با به روز رسانی مقدار Q جفت حالت در هر مرحله از قسمت به روز میکنیم. یک سیاست جدید از Q به روز شده در هر مرحله از قسمت استخراج خواهیم کرد و از این سیاست جدید استفاده خواهیم کرد. (به یاد داشته باشید که انتخاب یک عمل در محیط با استفاده از سیاست epsilon حریصانه است اما در حالی که به روز رسانی مقدار Q جفت اقدام حاللت بعدی از سیاست حریصانه استفاده میکنیم). بعد از چند قسمت، تابع Q مطلوب را خواهیم داشت.
Deep_Reinforcement_Learning_With_Python_Master_Classic_Rl,_Deep
Sudharsan Ravichandiran,2020
الگوریتم SARSA
در روش کنترل ، هدف پیدا کردن سیاست بهینه است، بنابراین با یک سیاست تصادفی اولیه شروع خواهیم کرد و سپس سعی خواهیم کرد که سیاست بهینه را به صورت تکراری پیدا کنیم.
در فصل قبلی، یاد گرفتیم که روش کنترل را می توان به دو دسته طبقه بندی کرد :
· کنترل سیاست On-policy control ))
· خارج از سیاست Off-policy control ))
در فصل قبلی یاد گرفتیم که کنترل سیاست و خارج از سیاست به چه معناست. در کنترل سیاست، عامل با استفاده از یک سیاست رفتار میکند و برای بهبود همان سیاست تلاش میکند. یعنی در این نوع سیاست، قسمتها را با استفاده از یک سیاست تولید میکنیم و همان سیاست را به طور تکراری برای پیدا کردن سیاست بهینه بهبود میدهیم.
در روش کنترل خارج از سیاست، عامل با استفاده از یک سیاست رفتار میکند و سعی میکند سیاست دیگری را بهبود بخشد. به این معنا است که، در روش خارج از سیاست، قسمتها را با استفاده از یک سیاست تولید میکنیم و سعی میکنیم یک سیاست متفاوت را برای پیدا کردن سیاست بهینه بهبود دهیم.
در حال حاضر، یاد خواهیم گرفت که چگونه وظایف کنترلی را با استفاده از یادگیری TD انجام دهیم. اول، درباره چگونگی کنترل TD را با کنترل سیاست و سپس در مورد خارج از سیاست توضیح خواهیم داد.