DRL:Deep Reinforcement Learning
یادگیری تقویتی عمیقDRL:Deep Reinforcement Learning
یادگیری تقویتی عمیق
یادگیری و انواع آن
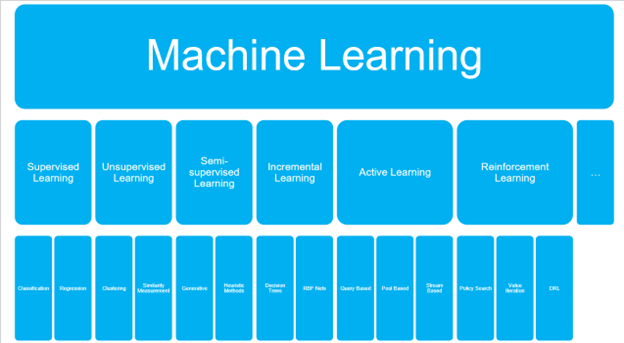
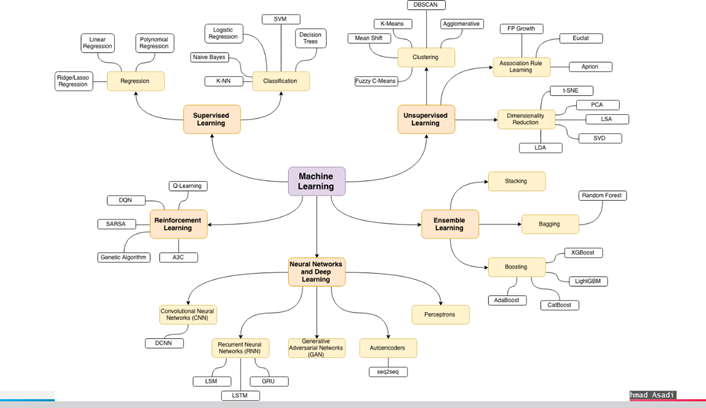
یادگیری ماشین شامل چهار شاخه است که عبارتند از:
1-یادگیری با ناظر
2- یادگیری بدون ناظر
3- یادگیری نیمه نظارتی
4- یادگیری تقویتی
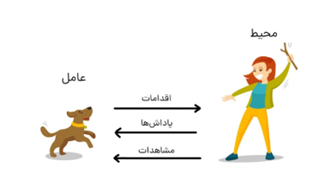
لذا یادگیری تقویتی (RL) یکی از زمینه های یادگیری ماشین (ML) است. بر خلاف سایر پارادایم های ML، مانند یادگیری تحت نظارت و بدون نظارت، دادهها در RL در یک مد ازمون و خطا ، از طریق تعامل با محیط خود جمع آوری می گردند.
RL یکی از فعال ترین زمینه های تحقیق در هوش مصنوعی است و اعتقاد بر این است که RL ما را یک گام به سمت دستیابی به عمومی شدن هوش مصنوعی نزدیک تر میکند . RL به سرعت در چند سال گذشته با طیف گسترده ای از برنامه های کاربردی اعم از ساخت سیستم های اتومبیل های خودران تکامل یافته است.
دلیل اصلی این تکامل ظهور یادگیری تقویتی عمیق است که ترکیبی از یادگیری عمیق و RL است. با ظهور الگوریتمها و کتابخانههای جدید یادگیری تقویتی ، این یادگیری به وضوح یکی از امیدوار کننده ترین قسمتهای یادگیری ماشین است.
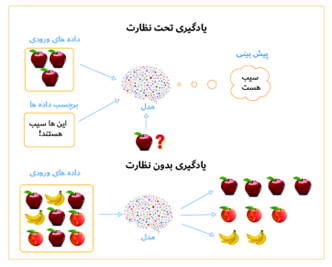
در یادگیری تحت نظارت، ماشین از داده های اموزشی یاد میگیرد. داده های اموزشی شامل یک جفت برچسب ورودی و خروجی است. بنابراین، ما مدل (عامل) را با استفاده از داده های اموزشی اموزش میدهیم به گونه ای که مدل میتواند یادگیری خود را به اطلاعات جدید دیده نشده تعمیم دهد. این یادگیری تحت نظارت نامیده میشود زیرا دادههای اموزشی به عنوان یک ناظر، که دارای جفت برچسب ورودی و خروجی است و مدل را هدایت می کند.
بیایید تفاوت بین یادگیری تحت نظارت و تقویتی را با یک مثال درک کنیم. مثال سگ را در نظر بگیرید. در یادگیری تحت نظارت، برای اموزش سگ برای گرفتن یک توپ، ما ان را به صراحت اموزش خواهیم داد با مشخص کردن قالب دادههای اموزشی چرخش به سمت چپ، رفتن به راست، حرکت به جلو هفت مرحله، گرفتن توپ، و غیره. اما در RL، ما فقط یک توپ پرتاب میکنیم، و هر بار سگ توپ را میگیرد، ما به او یک کوکی (پاداش) میدهیم. بنابراین، سگ یاد خواهد گرفت که توپ را بگیرد و تلاش میکند تا کوکی ها (پاداش) که می تواند دریافت کند را به حداکثر برساند.
بیایید یک مثال دیگر را در نظر بگیریم. در اموزش مدل در بازی شطرنج با استفاده از نظارت بر یادگیری، داده های اموزشی شامل تمام حرکت یک بازیکن در هر حالت است، که همراه با برچسب نشان می دهد که ایا حرکت خوبی است یا نه. سپس، ما مدل را اموزش می دهیم تا از این داده های اموزشی یاد بگیرد، در حالی که در مورد RL، عامل هیچ نوع اطلاعات اموزشی دریافت نخواهد کرد. در عوض، فقط به عامل برای هر کاری که انجام میدهد پاداش میدهیم. سپس، عامل یاد خواهد گرفت با تعامل با محیط و بر اساس پاداشی که دریافت میکند، اقدامات خوب را انتخاب کند.
شبیه به یادگیری تحت نظارت، در یادگیری بدون نظارت، ما مدل (عامل) را بر اساس داده های اموزشی اموزش میدهیم اما در مورد یادگیری بدون نظارت، داده های اموزشی هیچ برچسبی ندارد. یعنی فقط شامل ورودی ها است و نه خروجی ها. هدف از یادگیری بدون نظارت، تعیین الگوهای پنهان در ورودی است. یک تصور غلط رایج این است که RL نوعی یادگیری بدون نظارت است، اما اینطور نیست. در یادگیری بدون نظارت، مدل ساختار پنهان را یاد میگیرد، در حالی که در RL، مدل با به حداکثر رساندن پاداش یاد میگیرد.
در یادگیری نیمه نظارتی ﻳﺎﺩگیرﻧﺪﻩ ﻳﻚ ﻧﻤﻮﻧﻪ ﺁﻣﻮﺯﺷﻲ ﻣﺘﺸﻜﻞ ﺍﺯ ﺩﺍﺩﻩﻫﺎﻱ ﺑﺮچسبﺩﺍﺭ ﻭ ﺑﺪﻭﻥ ﺑﺮچسب ﺩﺭﻳﺎﻓﺖ ﻣﻲﻛﻨﺪ ﻭ ﺑﺮﺍﻱ ﺗﻤﺎﻡ ﻧﻘﺎﻁ ﺩﻳﺪﻩ ﻧﺸﺪﻩ پﻴﺶﺑﻴﻨﻲ ﻣﻲ ﻛﻨﺪ. ﻳﺎﺩگﻴﺮﻱ ﻧﻴﻤﻪﻧﻈﺎﺭﺗﻲ ﺩﺭ ﺗﻨﻈﻴﻤﺎﺗﻲ ﺭﺍﻳﺞ ﺍﺳﺖ ﻛﻪ ﺩﺍﺩﻩﻫﺎﻱ ﺑﺪﻭﻥ ﺑﺮچسب ﺑﻪﺭﺍﺣﺘﻲ ﺩﺭﺩﺳﺘﺮﺱ ﻫﺴﺘﻨﺪ ﺍﻣﺎﺩﺭﻳﺎﻓﺖ ﺑﺮچسبﻫﺎ گرﺍﻥ ﺍﺳﺖ. ﺍﻧﻮﺍﻉ ﻣﺨﺘﻠﻔﻲ ﺍﺯ ﻣﺴﺎﺋﻞﺍﺯ ﺟﻤﻠﻪ ﻃﺒﻘﻪﺑﻨﺪﻱ، ﺭگرﺳﻴﻮﻥ ﻳﺎ ﺭﺗﺒﻪﺑﻨﺪﻱ ﻭﻇﺎﻳﻒ، ﻣﻲﺗﻮﺍﻧﻨﺪ ﺑﻪ ﻋﻨﻮﺍﻥ ﻧﻤﻮﻧﻪﻫﺎﻳﻲ ﺍﺯ ﻳﺎﺩگﻴﺮﻱ ﻧﻴﻤﻪ ﻧﻈﺎﺭﺕ ﺷﺪﻩ ﺩﺭ ﻧﻈﺮ گرﻓﺘﻪ ﺷﻮﻧﺪ.

منبع:
,Deep_Reinforcement_Learning_With_Python_Master_Classic_Rl,_Deep ,
Sudharsan Ravichandiran,2020


























