DRL:Deep Reinforcement Learning
یادگیری تقویتی عمیقDRL:Deep Reinforcement Learning
یادگیری تقویتی عمیق
یادگیری تقویتی چیست؟
- عناصر کلیدی RL
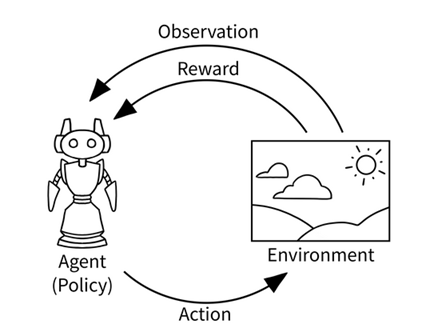
برخی از عناصر کلیدی RL موارد زیر را شامل میشود.
1- عامل (Agent)
عامل یک برنامه نرم افزاری است که تصمیم گیری هوشمندانه را یاد میگیرد. می توانیم بگوییم که یک عامل یک یادگیرنده در تنظیمات RL است. به عنوان مثال، یک بازیکن شطرنج به عنوان یک عامل در نظر گرفته شده است، زیرا بازیکن یاد میگیرد که بهترین حرکت (تصمیم گیری) را برای برنده شدن در بازی انجام دهد.
به طور مشابه، ماریو در بازی ویدئویی برادران سوپر ماریو را میتوان در نظر گرفت. ماریو یک عامل است که با بررسی بازی، یاد میگیرد که بهترین حرکت در بازی را انجام دهد.
2- محیط (Environment)
محیط، دنیای عامل است. عامل در محیط حرکت میکند. به عنوان مثال، در بازی شطرنج ، صفحه شطرنج محیط نامیده میشود.
که بازیکن شطرنج (عامل) یاد میگیرد که بازی شطرنج را در صفحه شطرنج انجام دهد (محیط). به طور مشابه، در برادران سوپر ماریو، دنیای ماریو محیط نامیده میشود.
3- وضعیت و عمل (State and Action)
وضعیت، یک موقعیت یا یک لحظه در محیطی است که عامل میتواند در ان باشد. بسیاری از موقعیتها برای عامل در محیط وجود دارد و این موقعیتها state نامیده میشوند.
به عنوان مثال، در بازی شطرنج ، هرموقعیت در صفحه شطرنج، وضعیت نامیده میشود. که معمولا با S نشان داده میشود.
لذا عامل با محیط ارتباط برقرار می کند و با انجام یک عمل (Action) از یک حالت به حالت دیگر حرکت می کند. در محیط بازی شطرنج، عمل، همان حرکت انجام شده توسط بازیکن (عامل) است. عمل را معمولا با a نمایش میدهند.
4- پاداش(Reward)
عامل با انجام یک عمل با یک محیط ارتباط برقرار میکند و از یک حالت به حالت دیگر منتقل میشود. بر اساس عمل، عامل پاداش دریافت میکند. پاداش چیزی جز یک مقدار عددی نیست، مثلا +1 برای یک عمل خوب و -1 برای یک عمل بد است. سوال پیش میآید که چگونه تصمیم بگیریم که یک عمل خوب یا بد است؟
در مثال بازی شطرنج ، اگر عامل حرکتی را انجام دهد که در ان یکی از قطعات حریف از بازی خارج شود، ان را یک عمل خوب در نظر گرفته و عامل پاداش مثبت دریافت میکند. به طور مشابه، اگر عامل حرکتی را انجام دهد که منجر به بازی بهتری برای حریف شود ان را یک عمل بد درنظر گرفته و عامل پاداش منفی دریافت میکند. پاداش با R مشخص میشود.
ایده اصلی RL
بیایید با یک قیاس شروع کنیم. بیایید فرض کنیم که در حال اموزش یک سگ (عامل) برای گرفتن یک توپ هستیم. به جای اموزش صریح به سگ برای گرفتن توپ، ما فقط یک توپ پرتاب میکنیم و هر بار که سگ توپ را میگیرد، ما به سگ یک کوکی (پاداش) میدهیم. اگر سگ توپ را نگیرد، ما به اوکوکی نمیدهیم. بنابراین، سگ خواهد فهمید چه عملی باعث میشود که یک کوکی دریافت کند و ان عمل را تکرار میکند. . سگ درک میکند که گرفتن توپ باعث شده است که یک کوکی دریافت کند و سعی خواهد کرد که گرفتن توپ را تکرار کند. بنابراین، به این ترتیب، سگ یاد خواهد گرفت که با هدف به حداکثر رساندن کوکی هایی که میتواند دریافت کند یک توپ را بگیرد.
به طور مشابه، در یک محیط RL، به عامل اموزش نمیدهیم که چه کاری انجام دهد یا چگونه ان را انجام دهد. در عوض، به عامل برای هر عملی که انجام می دهد پاداش می دهیم. پاداش مثبت به عامل زمانی که یک عمل خوب انجام میدهد و پاداش منفی به عامل زمانی که یک عمل بد را انجام می دهد خواهیم داد.
عامل توسط انجام یک عمل تصادفی شروع به حرکت میکند و اگر عمل خوب است، پس از ان پاداش مثبت میگیرد لذا عامل میفهمد که یک عمل خوب انجام داده است و ان عمل را تکرار خواهد کرد. اگر عمل انجام شده توسط عامل بد است، پس به عامل پاداش منفی میدهیم لذا عامل متوجه خواهد شد که ان عمل که انجام داده است بد است و این عمل را تکرار نمیکند.
بنابراین، RL را میتوان به عنوان یک فرایند یادگیری ازمون و خطا در نظر گرفت که در ان عامل تلاش میکند اقدامات مختلف و عمل خوب را یاد بگیرد که پاداش مثبت میدهد.
در قیاس سگ، سگ همان عامل را نشان می دهد و لذا پس از ان گرفتن توپ،کوکی را به سگ میدهد که یک پاداش مثبت است و ندادن کوکی پاداش منفی است. بنابراین، سگ (عامل) اقدامات مختلفی را بررسی میکند که آیا توپ را می گیرد یا نمیگیرد و درک میکند که گرفتن توپ یک عمل خوب است که برای سگ یک پاداش مثبت به ارمغان می اورد (گرفتن یک کوکی).
بیایید ایده RL را با یک مثال ساده تر بررسی کنیم. بیایید فرض کنیم که ما میخواهیم به یک ربات (عامل) اموزش دهیم که بدون ضربه زدن به کوه راه برود، همانطور که شکل 1.1 نشان می دهد:
ما به صراحت به ربات اموزش نخواهیم داد که در جهت کوه حرکت نکند. در عوض، اگر ربات به کوه برخورد کند و گیر کند، ما به ربات پاداش منفی می دهیم که به آن 1- میگویند. بنابراین، ربات درک خواهد کرد که ضربه زدن به کوه یک عمل اشتباه است و ان را تکرار نخواهد کرد.

به طور مشابه، هنگامی که ربات در مسیر درست بدون ضربه زدن به کوه راه میرود، به ربات پاداش مثبت میدهیم، مثلا +1. بنابراین، ربات درک خواهد کرد که ضربه نزدن به کوه یک عمل خوب است و این عمل را تکرار میکند:
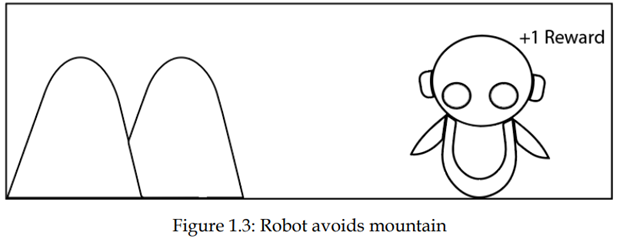
بنابراین، در تنظیم RL، عامل اقدامات مختلف را بررسی میکند و بهترین عمل را بر اساس پاداشهایی که به دست میآورد یاد میگیرد.
اکنون یک ایده اساسی از نحوه کار RL بیان شد، در بخش های اینده، به جزئیات بیشتر پرداخته میشود و همچنین مفاهیم مهم درگیر در RL را یاد میگیریم.
الگوریتم RL
مراحل در یک الگوریتم RL معمولی به شرح زیر است:
· اول، عامل با انجام یک عمل با محیط ارتباط برقرار می کند.
· با انجام یک عمل، عامل از یک حالت به حالت دیگر حرکت می کند.
· سپس عامل بر اساس عملی که انجام داده است پاداش دریافت خواهد کرد.
· بر اساس پاداش، عامل درک خواهد کرد که ایا عمل خوب است یا خیر
· اگر عمل خوب بود، یعنی اگر عامل پاداش مثبت دریافت کند، سپس عامل ترجیح می دهد این عمل را انجام دهد، در غیر این صورت عامل سعی خواهد کرد با انجام اقدامات دیگر در جستجوی پاداش مثبت باشد.
یادگیری تقویتی اساسا یک فرایند یادگیری ازمون و خطا است. حالا، بیایید بازی شطرنج خود را دوباره بررسی کنیم:
عامل (برنامه نرم افزار) بازیکن شطرنج است. بنابراین، عامل در تعامل با محیط (صفحه شطرنج) با انجام یک عمل (حرکت میکند). اگر عامل پاداش مثبتی برای یک عمل دریافت کند، ترجیح می دهد ان عمل را دوباره انجام دهد. در غیر این صورت یک عمل متفاوت را پیدا خواهد کرد که پاداش مثبت میدهد.
در نهایت، هدف عامل این است که پاداشی را که دریافت میکند به حداکثر برساند. اگر عامل پاداش خوبی دریافت کند، به این معنی است که کار خوبی انجام داده است. اگر عامل یک عمل خوب انجام دهد، به این معنی است که می تواند بازی را برنده شود. بنابراین، عامل یاد می گیرد برای برنده شدن در بازی باید پاداش را به حداکثر برساند.
عامل RL درمحیط شبکه
بیایید درک خود را از RL با نگاه کردن به یک مثال ساده دیگر تقویت کنیم. محیط شبکه زیر را در نظر بگیرید:
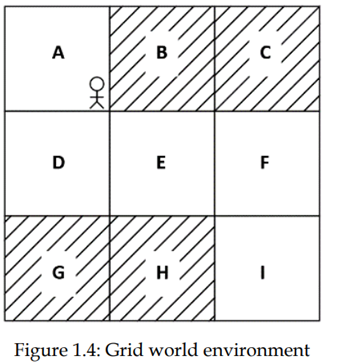
موقعیت های A تا I در محیط، حالتهای محیط نامیده میشود. هدف عامل این است که با شروع از موقعیت A بدون بازدید از حالت های سایه دار (B، C، G و H) به حالت I برسد. بنابراین، برای رسیدن به هدف، هر زمان که عامل از یک حالت سایه دار بازدید میکند، پاداش منفی (مثلا -1) به او میدهیم و زمانی که از یک حالت بدون سایه بازدید میکند، یک پاداش مثبت (+1) به او میدهیم. برای حرکت در محیط میتواند حرکت به بالا، پایین، راست و چپ داشته یاشد.
اولین باری که عامل با محیط ارتباط برقرار میکند (اولین تکرار)، عامل بعید است که عمل صحیح را در هر حالت انجام دهد و بنابراین پاداش منفی دریافت میکند. به عبارت دیگر، در تکرار اول، عامل یک عمل تصادفی را در هر یک حالتها انجام میدهد و این ممکن است منجر به دریافت پاداش منفی شود. اما با تکراهای بعد، عامل یاد میگیرد برای انجام عمل صحیح در هر حالت از طریق پاداشی که به دست میاورد به او کمک میکند تا به هدف برسد.
اجازه دهید این را با جزئیات بررسی کنیم:
تکرار 1
همانطور که متوجه شدیم، در تکرار اول، عامل یک عمل تصادفی را در هر حالت انجام میدهد. به عنوان مثال، به شکل زیر نگاه کنید. در تکرار اول، از حالت A عامل به سمت راست حرکت میکند و به حالت جدید B میرسد. اما از انجا که B حالت سایه است، عامل پاداش منفی دریافت خواهد کرد و بنابراین عامل درک خواهد کرد که این حرکت درست نیست. لذا دفعه بعد، به جای حرکت به سمت راست متفاوت عمل خواهد کرد: همانطور که شکل 1.5 نشان می دهد، از حالت B، عامل به پایین حرکت می کند و به حالت جدید E می رسد. از انجا که E یک حالت بدون سایه است، عامل پاداش مثبت دریافت خواهد کرد، بنابراین عامل درک خواهد کرد که حرکت از حالت B یک عمل خوب است.
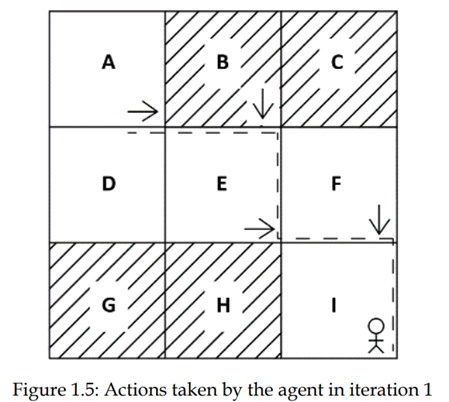
از حالت E، عامل به سمت راست حرکت می کند و به حالتF می رسد. از انجا که F یک حالت بدون سایه است، عامل پاداش مثبت دریافت میکند و درک میکند که حرکت به سمت راست از حالت E یک عمل خوب است. از حالت F، عامل به پایین حرکت میکند و به هدف که حالت I است میرسد و با دریافت پاداش مثبت، عامل درک خواهد کرد که حرکت پایین از حالت F یک عمل خوب است.
تکرار 2
در تکرار دوم، از حالت A، به جای حرکت به سمت راست، عامل سعی میکند یک عمل متفاوت نسبت به قبلی که اموخته است انجام دهد چون در تکرار اول یادگرفت که حرکت به سمت راست یک عمل خوب در حالت A نیست.
بنابراین، همانطور که شکل 1.6 نشان میدهد، در این تکرار عامل از حالت A به پایین حرکت میکند و به حالت D میرسد. از انجا که D یک حالت بدون سایه است، عامل پاداش مثبت دریافت میکند و لذا عامل درک خواهد کرد که حرکت به پایین یک عمل خوب در حالت A است.
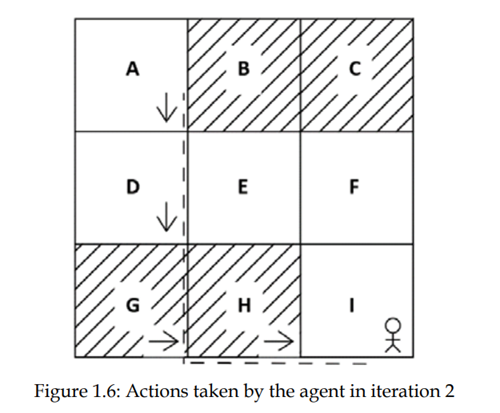
همانطور که در شکل قبلی نشان داده شده است، از حالت D، عامل به پایین حرکت میکند و به حالت D میرسد. اما از انجا که G یک حالت سایه دار است، عامل پاداش منفی دریافت خواهد کرد و بنابراین عامل درک خواهد کرد که حرکت به پایین یک عمل خوب در حالت D نیست و هنگامی که دفعه بعد از حالت D بازدید میکند، به جای حرکت پایین، یک عمل متفاوت را امتحان میکند. از G، عامل به سمت راست حرکت میکند و به حالت H میرسد. از انجا که H یک حالت سایه است، با دریافت پاداش منفی درک میکند که این حرکت در حالت D یک عمل خوب نیست. از H به سمت راست حرکت میکند و به حالت هدف I میرسد و پاداش مثبت دریافت میکند، بنابراین عامل متوجه خواهد شد که حرکت به سمت راست از حالت H یک اقدام خوب است.
تکرار 3
در تکرار سوم، عامل از حالت A پایین می رود، درتکراردوم، عامل اموخته است که حرکت به پایین یک عمل خوب در حالت A است. بنابراین عامل از حالت A به پایین حرکت می کند و به حالت بعدی، D می رسد، همانطور که شکل 1.7 نشان می دهد
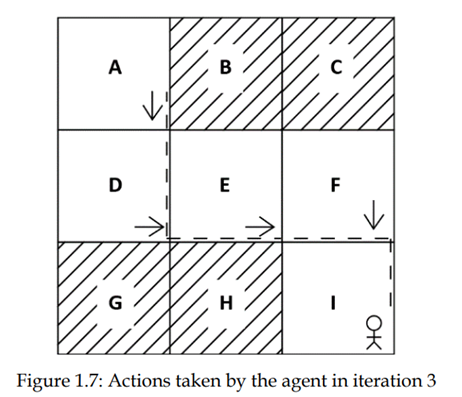
از حالت D، عامل تلاش میکند یک عمل متفاوت به جای حرکت به پایین انجام دهد زیرا در تکرار دوم، متوجه شد که حرکت به پایین یک عمل خوب در حالت D نیست. بنابراین، در این تکرار، عامل از حالت D به سمت راست حرکت میکند و به حالت E میرسد. از حالت E، عامل به سمت راست حرکت میکند، همانطور که عامل قبلا در تکرار اول اموخته است که حرکت به سمت راست از حالت E یک اقدام خوب است و به حالت F میرسد. اکنون، از حالت F، عامل به پایین حرکت میکند زیرا عامل در تکرار اول اموخته که حرکت به پایین یک عمل خوب در حالت F است، وباعث رسیدن به حالت هدف I میشود. شکل 1.8 نتیجه تکرار سوم را نشان می دهد:
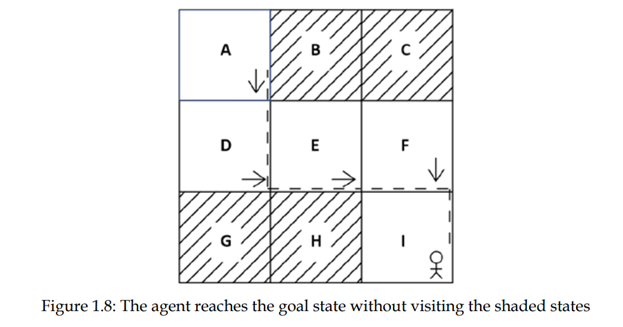
همانطور که می بینیم، عامل رسیدن به حالت هدف I از حالت A بدون بازدید از حالتهای سایه دار را بر اساس پاداش با موفقیت اموخته است.
به این ترتیب، عامل اقدامات مختلف را در هر حالت امتحان میکند و بر اساس پاداشی که به دست میآورد درک میکند که یک عمل خوب است یا بد. هدف عامل به حداکثر رساندن پاداش است. بنابراین، عامل همیشه سعی خواهد کرد اقدامات خوبی انجام دهد که پاداش مثبتی میدهد تا به هدف نهایی برسد.
توجه داشته باشید که این تکرارها، قسمت ها (episodes) در اصطلاحات RL نامیده میشوند
منبع:
,Deep_Reinforcement_Learning_With_Python_Master_Classic_Rl,_Deep ,
Sudharsan Ravichandiran,2020


























